引言 Link to heading
我们在课上学习了《基于 RAG 的问答系统》,介绍了 RAG 相关的属于概念、基本原理、系统架构等。我在课后额外阅读了关于 RAG 的论文和视频教程[1],深度探索了 RAG 的一些方式和技巧,以及在生产环境中部署 RAG 可能会遇到的问题和解决方案。因此本文将会对我学习 RAG 高阶技巧的过程进行总结,并提供对 RAG 性能调优的一些思考。
RAG 系统是一个基于检索的问答系统,它的核心是一个由三个部分组成的模型:Indexer, Retriever 和 Generator。Indexer 将文档进行拆分和索引,Retriever 用于检索相关的文档,Generator 用于生成答案。RAG 系统的优势在于它可以在大规模的文档集合中检索答案,而不需要对所有文档进行检索。这使得 RAG 系统在大规模文档集合中的问答任务中具有很大的优势。
当前公开的大语言模型往往基于公开数据集或者公开网站的数据训练,然而基于微软的研究报告,95% 的数据都存储在私有企业服务器中[2],因此 LLM 模型的能力会受到极大限制。此外,很多知识点都在不断更新,LLM 训练阶段的数据可能已经过时,甚至完全错误。RAG 系统通过将检索和生成分开,可以在检索阶段使用最新的数据,从而提高系统的准确性。
在实际应用中,RAG 系统的性能往往会受到很多因素的影响,比如检索速度、检索准确性、生成速度、生成准确性等。因此,对 RAG 系统的性能进行调优是非常重要的。在本文中,我将会介绍一些 RAG 系统的性能调优技巧,以及一些可能会遇到的问题和解决方案。
RAG 系统架构 Link to heading
上文提到,一个简单的 RAG 系统就是将文档进行索引、检索和生成(图 1)。在课上我们已经学习过整个流程。但其实每个阶段都可以额外扩展出很多优化技巧。例如:如何创建索引、Prompt 调优、检索算法等。通过查阅相关文档和视频,我了解了目前主流的 RAG 调优技巧(图 2):从用户输入的问题出发,将流程拆分为查询翻译(Query Translation)、路由(Routing)、查询构建(Query Construction)、索引(Indexing)、检索(Retrieval)、生成(Generation)多个阶段,每个阶段都有许多技巧提升模型表现。
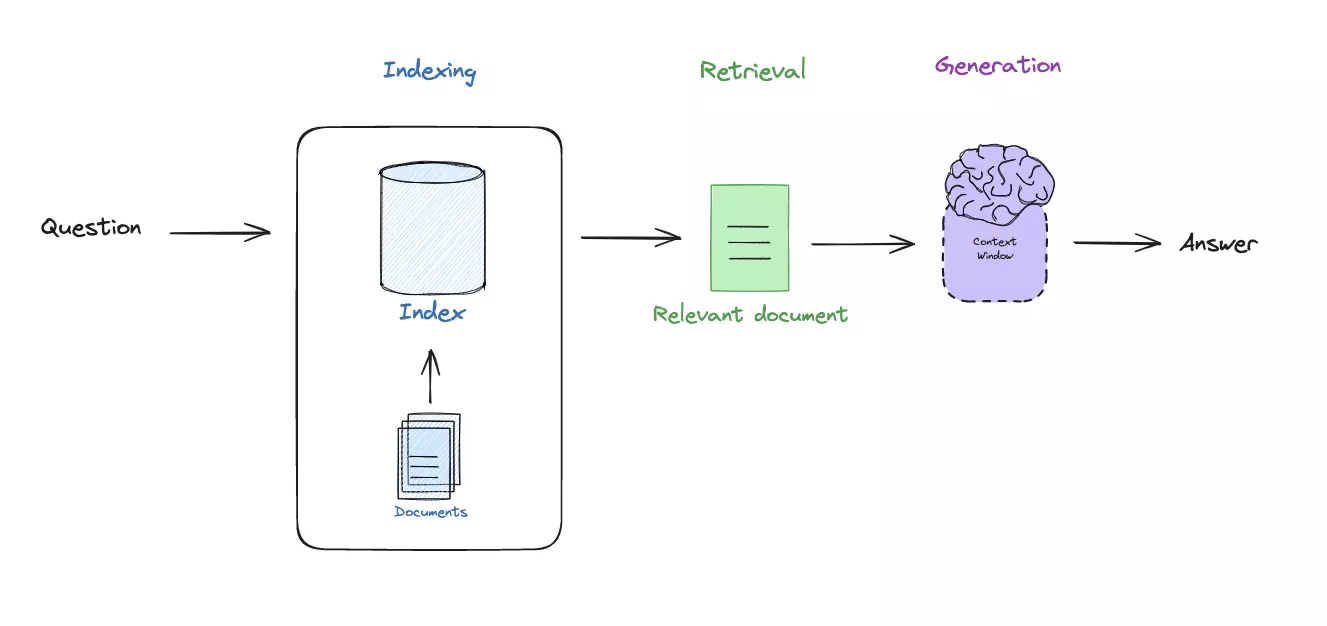
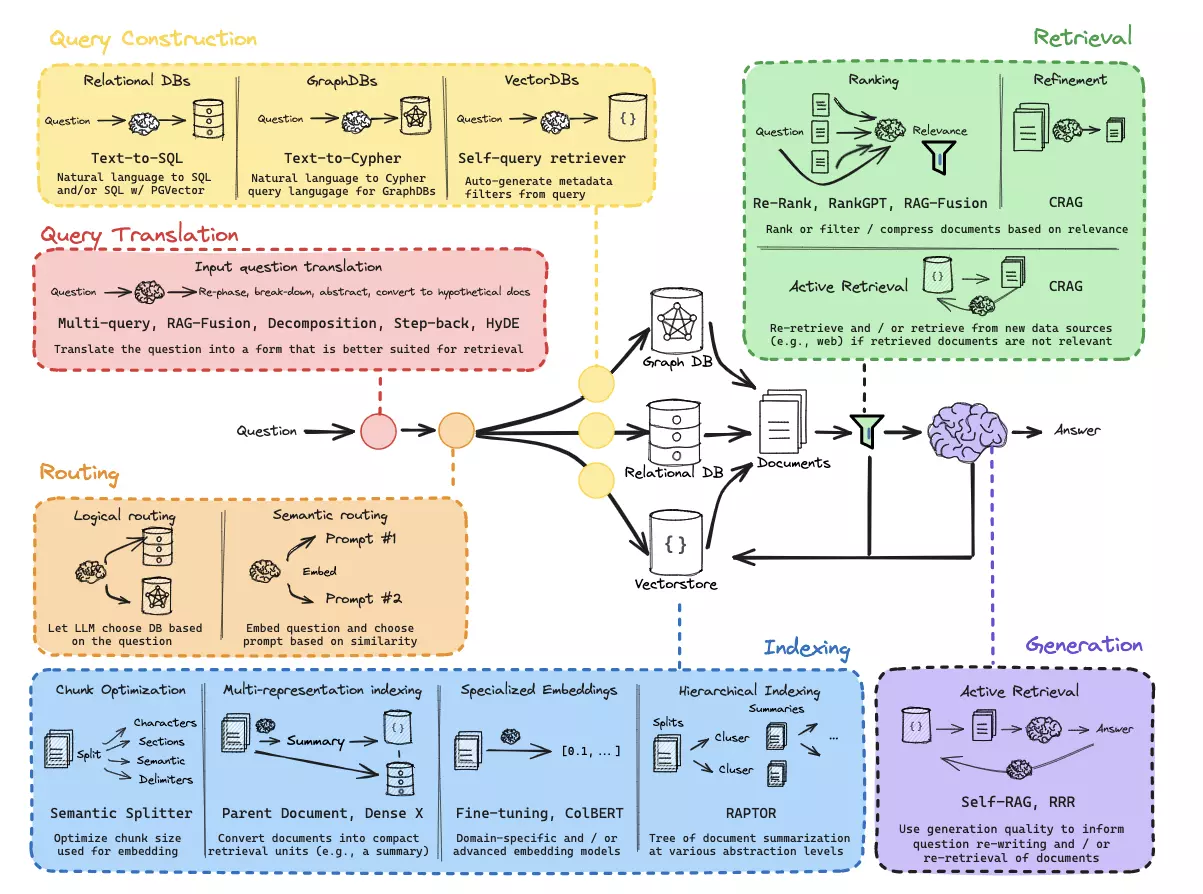
本文将按照 RAG 系统复杂结构图的各个阶段,逐一介绍 RAG 系统的性能调优技巧。我使用 LangChain 的相关框架库,对每种技巧都做了具体实现,最终的附件可见。
查询翻译 Query Translation Link to heading
查询翻译的目的是将用户的问题按照某些技巧“翻译”一下,使得真正用于检索的问题更加准确。直接在词嵌入(Word Embedding)上做语义搜索的准确率是很难保证的,如果用户提供了一个语义不清的问题,那么基于这个问题检索到的文档很可能也会语义不清,进而导致 LLM 模型出现幻觉。
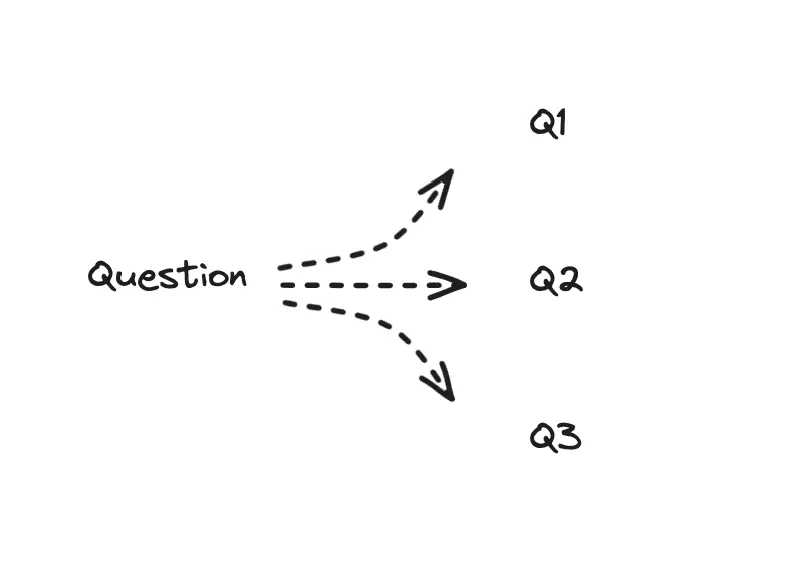
将用户的查询进行翻译的技巧有很多,我们可以从查询的抽象程度出发来思考。如果要减少抽象,可以把用户的问题分解为子问题,进行分别检索(Decomposition);要提高抽象程度,就要对问题进行归纳,找到其本质的问题(Step-back);此外,还可以不改变抽象程度,对用户的问题进行重写,从不同角度来解释问题(Multi-query, RAG-Fusion)。
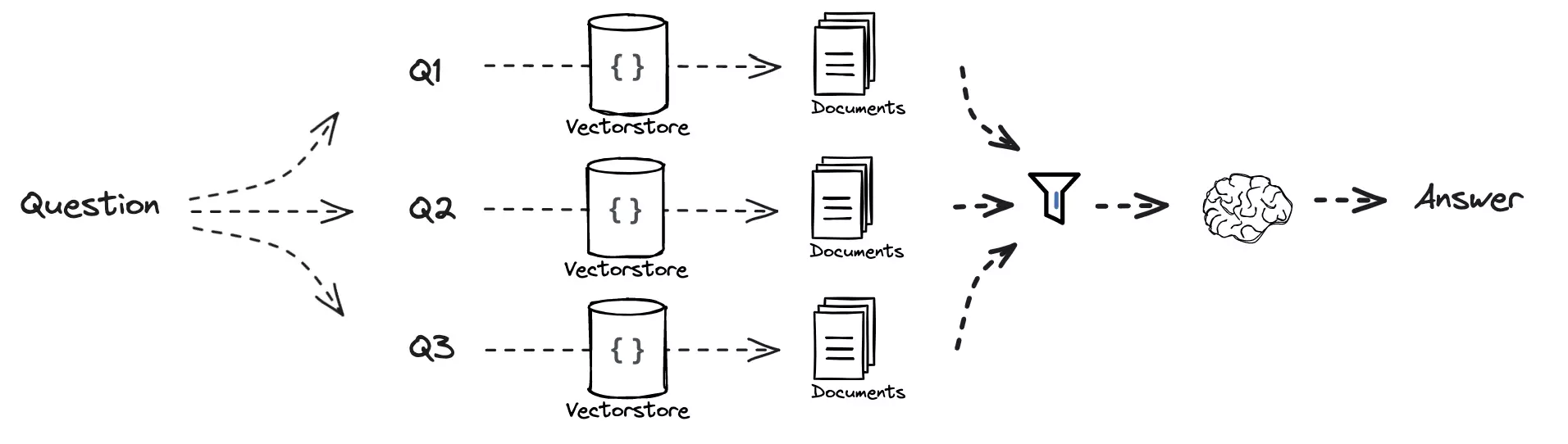
无论是哪一种技巧,最终结果都是将一条用户的提问“翻译”成为多条检索问题,然后对问题进行逐个检索以提高模型的表现。这些新生成的问题在语义上可能会距离需要的信息更近,因而可以提高检索的准确性(图 3)。
Multi-query 与 RAG-Fusion Link to heading
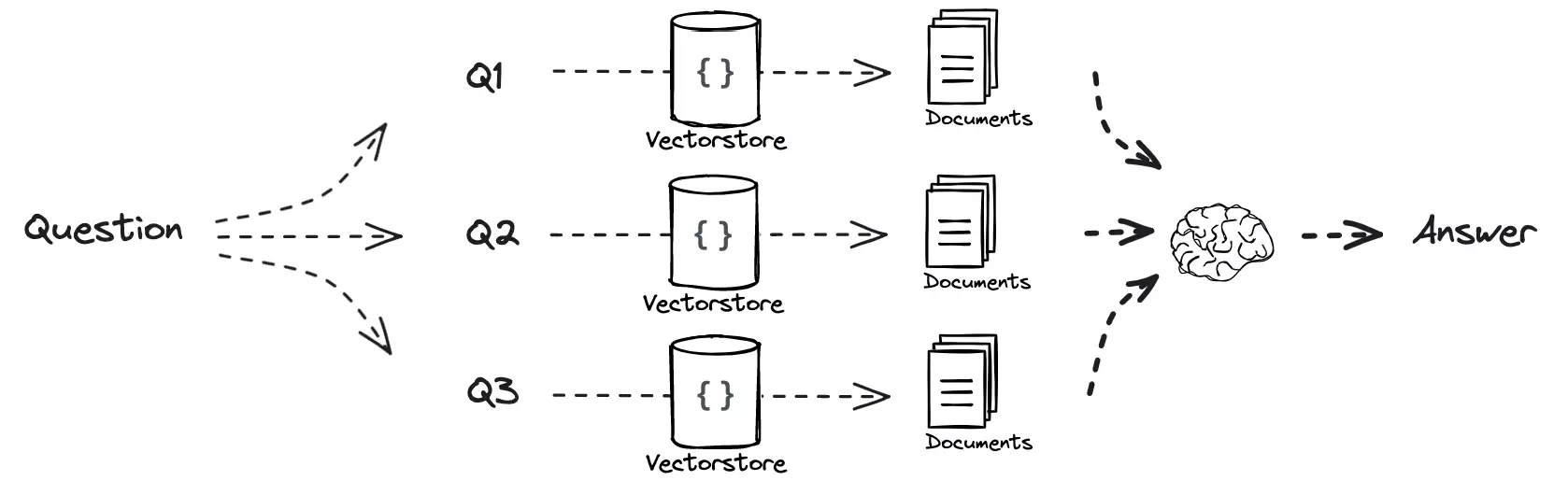
从最简单的 MultiQuery 开始介绍。MultiQuery 把用户的一个问题分解为多个类似的问题,然后分别交给下游进行检索。
MultiQuery 通常情况下会使用这样的 Prompt:
You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}
你是一位人工智能语言模型助手。你的任务是生成五个不同版本的给定用户问题,
以从向量数据库中检索相关文档。通过对用户问题进行多角度生成,
你的目标是帮助用户克服基于距离的相似性搜索的一些限制。
请提供这些替代问题,并用换行符分隔。原始问题:{question}
如果将 Multi-Query 检索出的文档列表,按照出现的次数、与问题之间的关联度进行重排序,就是 RAG-Fusion (图 5)的思想[3]。例如在多次检索中,有些文档重复出现了多次,而且排名很靠前,那么 Fusion 过程就会更高概率保留这些文档。相反有些文档只在某个单一子查询中出现,而且排名很低,那么就会在 Fusion 阶段中被删除。
Step-back 与 Decomposition Link to heading
后退(Step-back)和分解(Decomposition)分别是增加和减少抽象程度的技巧,重点在于对生成问题的 Prompt 的修改。
Step-back 方案通过将原问题转化成更抽象、通用的检索问题:
You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:
Q: Could the members of the police perform lawful arrests?
A: What can the members of the police do?
Q: Jan Sindel’s was born in what country?
A: What is Jan Sindel’s personal history?
你是世界知识的专家。你的任务是退后一步,将一个问题改述为一个更通用、更易回答的退后问题。以下是一些示例:
问:警察成员能执行合法逮捕吗?
答:警察成员能做什么?
问:Jan Sindel 出生在哪个国家?
答:Jan Sindel 的个人历史是什么?
相反,Decomposition 方案则是将原问题分解成多个子问题:
You are a helpful assistant that generates multiple sub-questions related to an input question.
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation.
Generate multiple search queries related to: {question}
Output (3 queries):
你是一个有用的助手,能够针对输入的问题生成多个相关的子问题。
目标是将输入拆分成一组可以单独回答的子问题/子查询。
生成与以下内容相关的多个搜索查询:{question}
输出(3个查询):
HyDE Link to heading
和通过修改问题抽象程度的方法相比,HyDE 方法采取了另一种思想[4]。直观考虑:与用户的问题语义最接近的资料,未必提供了问题的答案。例如,用户提问“北京气候怎么样”。可能最接近的文档是“北京天气怎么样?北京会不会下雨?北京下雪好看吗?”之类的一系列问题,而不是关于北京气候的答案文档。因此 HyDE 方法的思想是让 LLM 直接回答用户的问题,然后将回答的结果作为检索的问题,从而提高检索的准确性。
Please write a scientific paper passage to answer the question
Question: {question}
Passage:
请写一篇科学论文段落来回答问题
问题:{question}
段落:
路由 Routing Link to heading
路由既包括对资料库(数据源)的路由,也包括对问题翻译过程使用的 Prompt 的路由。
首先,RAG 系统的资料库往往是多源的。比如我们要查询 LangChain 的文档相关问题,因为 LangChain 同时提供了 Python 和 JavaScript 两种语言的 API,用户很可能只会提问关于其中一种编程语言的问题。因此在进行检索之前,RAG 系统应当识别出用户究竟需要从哪个数据源中抽取上下文信息。这在 Github Copilot 插件中就有体现,用户在 Visual Studio Code 编辑器中编写代码时,Copilot 会根据用户打开的文件类型来判断用户的代码是何种编程语言,进而调用对应编程语言的大模型来补全代码。
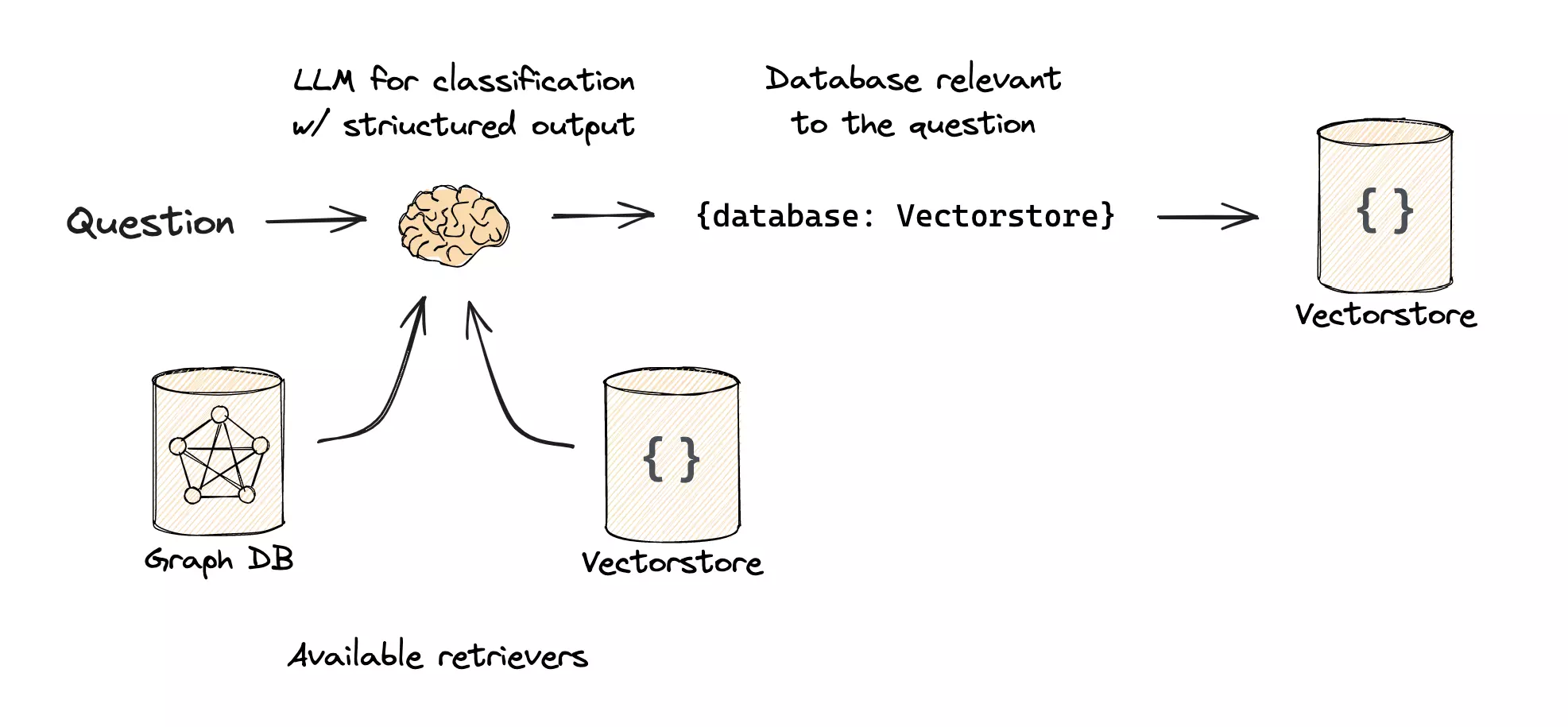
对于一个通用的 RAG 系统,可能有矢量数据库(Vector Database)用来存储自然语言,也有 SQL 数据库用来存储结构化的数据,甚至是图数据库用来存储知识图谱。在路由阶段,我们需要根据用户的问题类型,将问题路由到不同的检索模块中。可以利用 LLM 的能力,将所有数据库的元信息描述给 LLM,附加上用户的问题,让 LLM 来判断从哪个数据库中检索。
另一方面,针对不同问题的重写任务,可能需要不同的 Prompt 来描述。比如一个回答不同学科知识的 RAG 系统,针对用户提出的“语文”问题和“数学”问题,很可能需要不同的 Prompt 来对问题进行分解。
语文:你是一位非常优秀的语文老师。你擅长从文学性、语言性、修辞性等多个角度分解一个问题。
问题:{question}
数学:你是一位非常优秀的数学家。你擅长回答数学问题。你之所以如此出色,是因为你能够将复杂的问题分解成各个组成部分,解答这些组成部分,然后将它们整合起来回答更广泛的问题。
问题:{question}
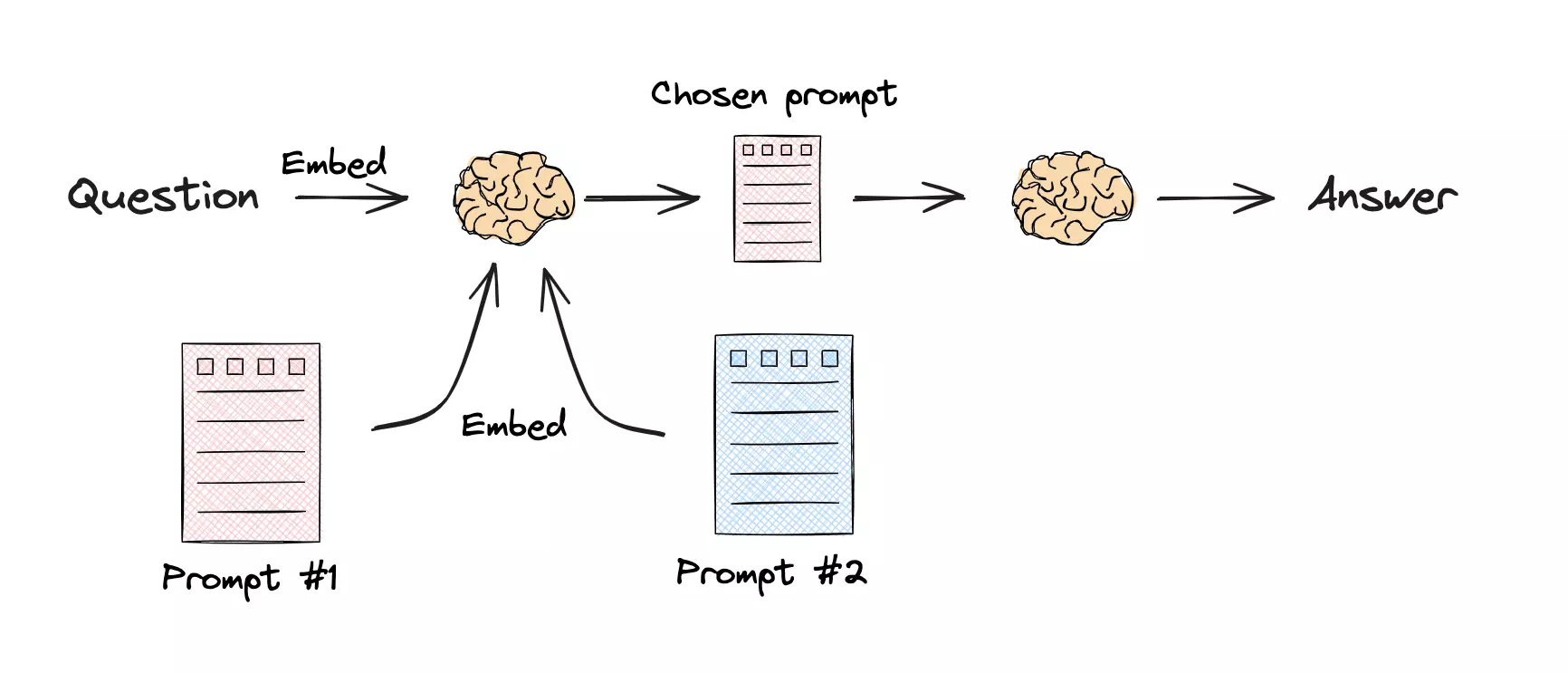
通过将用户的问题、不同的 Prompt 全部转化成词嵌入,然后与用户提问语义距离最接近的 Prompt 进行回答,实现了对 Prompt 的路由。
查询构建 Query Construction Link to heading
用户的问题可能不是简单从矢量数据库中提取相似的文本就能解决的。用户可能会询问一些数据源的特定问题,例如“给我 2024 年北京大学官网发布的文章数量”,此时用词嵌入 + 语义相似度的技巧就很难解决了。但如果数据源中有 SQL 数据库,那么一条简单的 SQL 语句可能就能解决这个问题。Query Construction 阶段的任务就是将用户的问题转化成适合检索的形式,或者说是将用户的自然语言转化成数据源支持的领域特定语言(DSL)。比如我们可以借助 Function Calling 的技巧,将用户的问题转化成函数调用,然后将函数调用转化成 SQL 语句。这样就可以实现用户的问题到 SQL 语句的转化。
你擅长将用户问题转换为数据库查询。
您可以访问一个关于北京大学官网发布文章的 SQL 数据库。
给定一个问题,返回一个优化后的数据库查询,以检索最相关的结果。
如果遇到不熟悉的缩写或词汇,请不要尝试改述它们。
数据库字段:{fields}
问题:{question}
除了 SQL 形式的数据源,图数据库、知识图谱等数据源也可以通过类似的方法进行查询构建。通过将用户的问题转化成领域特定语言,可以提高检索的准确性。
索引 Indexing Link to heading
我们在课上已经知道,对于比较长的文档,可以通过分块的方式将文档转化成词嵌入,然后存储到向量数据库中。在分块过程中,可以通过改变分块大小、相邻分块之间重叠的字符数量等方式来提高检索准确性。假设我们在构建关于一本教材的 RAG 系统,因为教材最多只有百万级别的 token 数量,我们可以直接讲文档拆分、转换为词嵌入、存储到向量数据库中。但是如果我们要构建一个大型 RAG 系统,比如构建一个类似 Google 的 RAG 系统,我们就要考虑对文档进行合适的转换后存储到向量数据库。
多表征索引 Multi-representation Indexing Link to heading
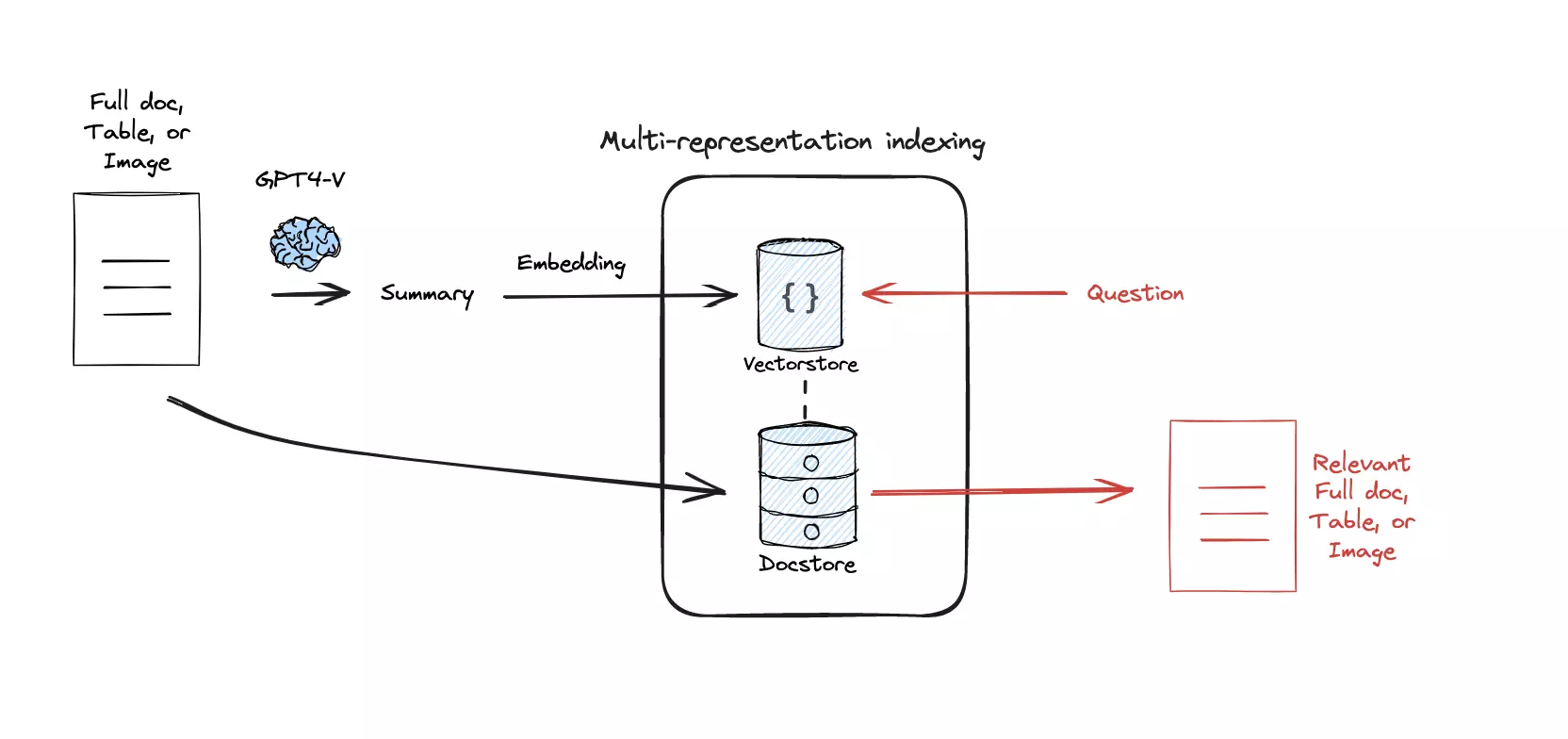
其中一个方案就是多表征索引(Multi-representation Indexing),即将一份文档利用 LLM 总结成一条或者若干条短文本,只将短文本转化为词嵌入并存储到向量数据库中[5]。当用户的问题匹配到某条短文本时,再将其对应的文档从文档数据库中检索出来(图 8)。这种方式可以看作是对文档的蒸馏(Distillation),既减少了向量数据库的存储空间和检索时间,如果蒸馏效果足够好,也可以提升检索的准确性。
Summarize the following document:
{doc}
总结以下文档:
{doc}
分层索引 Hierarchical Indexing Link to heading
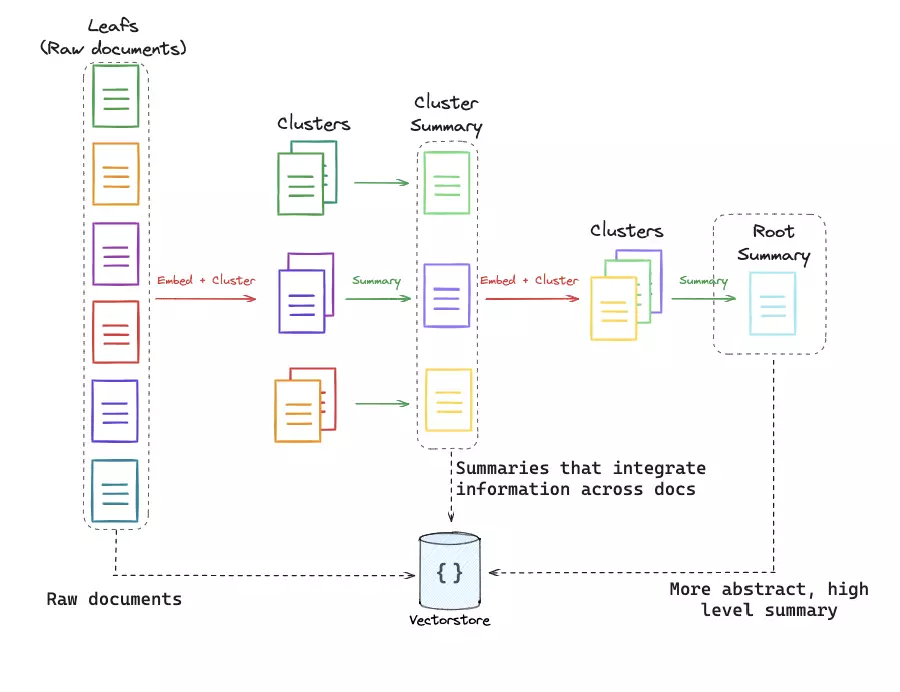
多表征所有将每个文档映射到一段或者多段短文本,而分层索引(Hierarchical Indexing)则是将文档映射到多个层次的短文本。假设一系列文档出发,首先按照语义相似度对文档进行分组,然后对每组分别利用 LLM 进行总结,再对总结内容进行分组、总结,直到最终得到一条关于所有文档的总结(Root Summary,图 9)。在检索阶段,不同层级的总结都会被进行语义相似度对比,这样就可以对应到不同抽象“层级”的问题。
特化词嵌入 Specialized Embeddings Link to heading
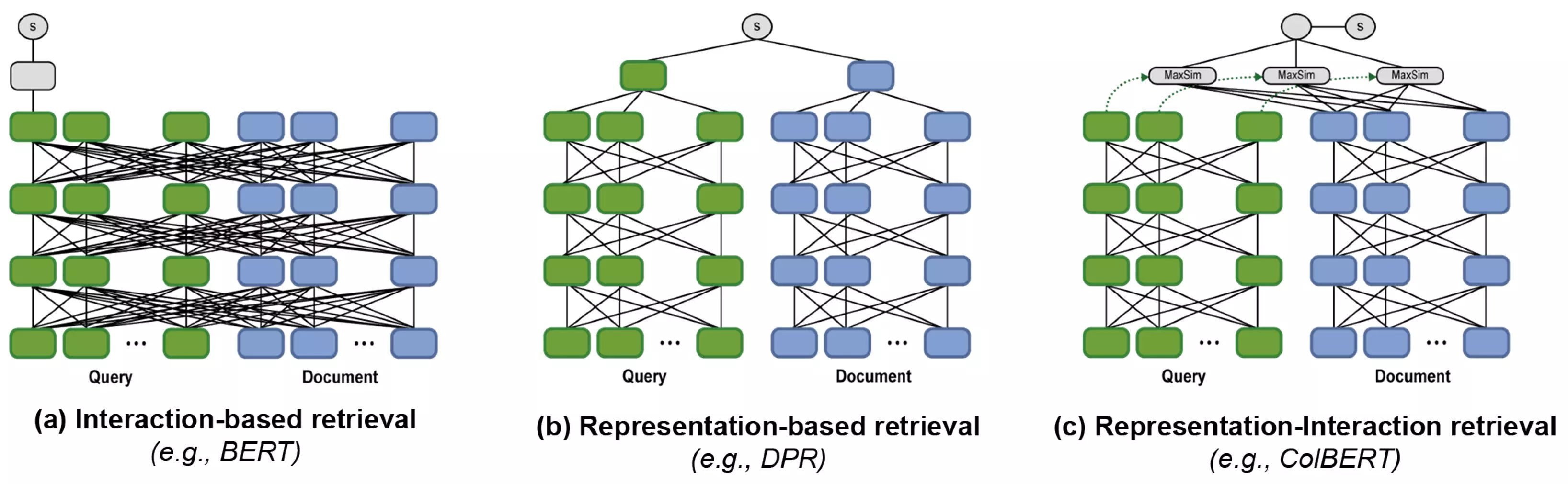
RAG 系统依赖词嵌入来抽取语义特征,最终服务于检索。而常见的词嵌入模型往往是服务于通用文本生成的(如 Bert,OpenAIEmbedding 等),可能会和检索任务有差异。因此,利用 Fine-tuning 可以优化词嵌入模型来服务于检索。此外,上面提到的词嵌入转化都是将一整片文档,或者拆分后的整段文档转化为一条词嵌入。ColBERT 方法[6]则是把文档和用户提问全部拆分为 token,然后将每个 token 转化为词嵌入,通过计算 maxsum,来作为文本相似度指标。实验证明这种转化方案可以提高检索的准确性。
检索 Retrieval Link to heading
我们在课上提到过 RAG-Fusion, 重排序, 子查询等等检索优化方案。这里我想额外介绍一个用来进行“动态 RAG”的方案:纠错检索增强生成(Corrective RAG,CRAG)[7]。通过对检索的文档进行相关性评估(用置信度来恒量),判断取回的文档究竟是“正确”、“模糊”还是“错误”,来动态调整交给生成器的文档。实验证明,CRAG 方法可以提高 RAG 系统的检索准确性,尤其是在检索文档置信度较低的情况下。
- 如果文档置信度较高,通过一个叫做知识精炼(Knowledge Refinement)的技术,将文档分解、筛选、重新结合成内部知识 kin,作为传递给下游的知识。
- 如果文档置信度较低,直接忽略这些文档,选择从互联网中进行检索到知识 kex,传递给下游推理。
- 如果文档置信度一般,那么既从文档进行知识精炼获得 kin,又从互联网检索到知识 kex,将两部分知识一起传递给下游。
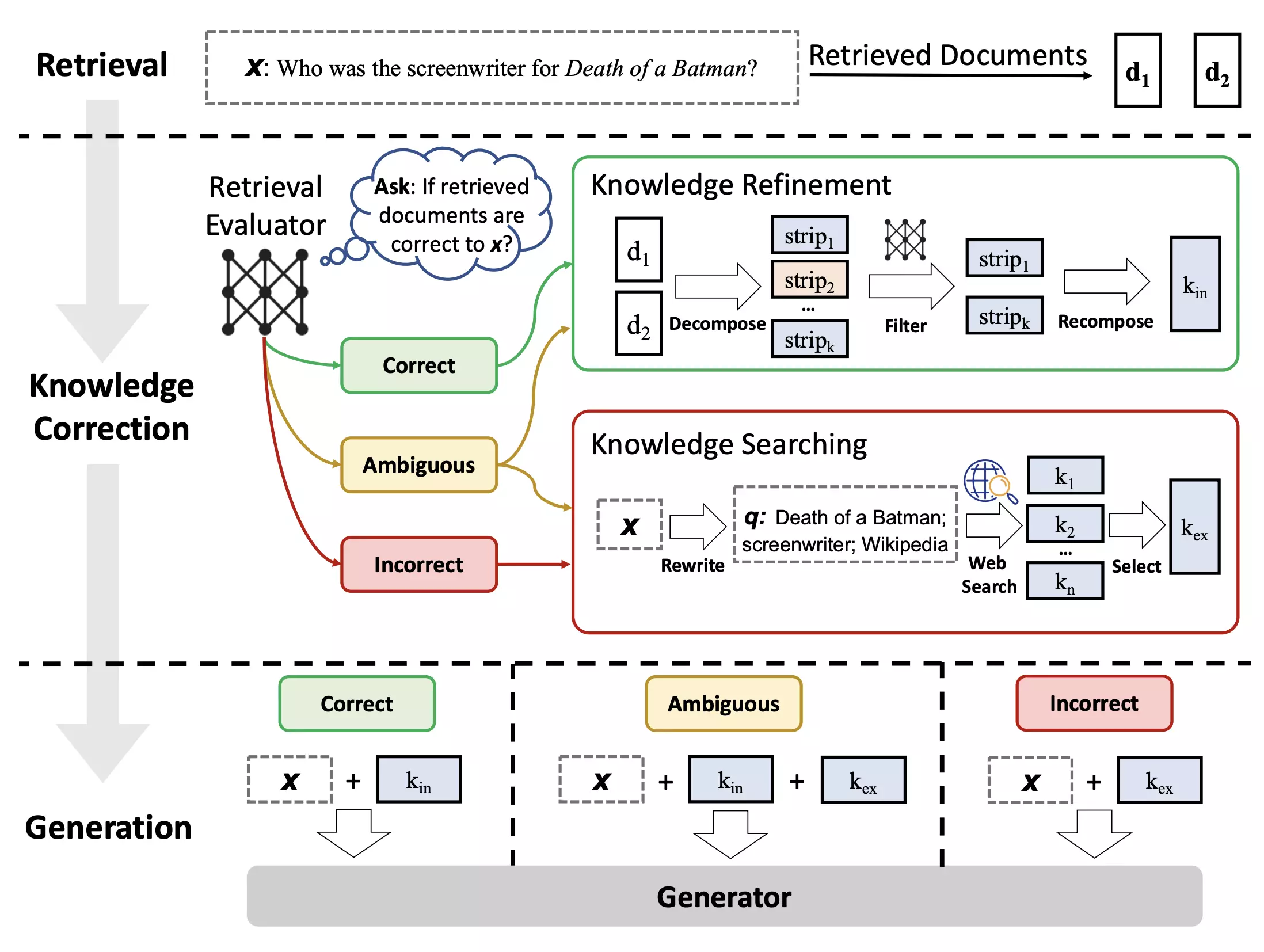
Crag 相当于是将互联网检索作为整个 RAG 系统的后备方案。结合上次调研的 LangChain 框架下的 LangGraph 工具,这种动态调整的检索方案可以快速实现。
CRAG 是通过评估检索文档的质量来进行动态决断,还有一种方案是通过对用户问题的分类进行动态决断——Adaptive RAG[8]。

Adaptive RAG 使用一个分类器来判断当前问题是直白查询(Straightforward Query)、简单查询(Simple Query)还是复杂查询(Complex Query),直白查询直接忽略检索阶段,简单查询只进行一次检索,复杂查询进行多轮检索,生成中间答案。这种动态调整的检索方案在回答时间和回答精度之间取得了平衡。
RAG 的未来发展 Link to heading
从 GPT-3.5 到 GPT-4,再如 Anthropic 的 Claude-Opus 和月之暗面的 Kimi Chat,大语言模型的上下文长度日渐增长,此外,诸如“大海捞针”的实验也证明模型对长上下文的信息提取能力也日渐提高了。因此,有人怀疑如果大语言模型的上下文长度足以包括所有数据,那么对 RAG 系统的优化可能就无关紧要了。但个人认为,一方面,构建通用的 RAG 系统所支持的海量数据集是永远无法被长上下文替代的;另一方面,实验证明如果直接给模型提供大量文本并依赖“大海捞针”的能力,其推理能力会随着提供文本长度的增加而下降[9]。因此,用 RAG 系统来提供相关信息的能力还是非常有必要的。
RAG 系统也不会是一成不变的范式,RAG 检索准确度未来一定会越来越高(越来越多的技巧被提出)。模型本身的能力提升(推理能力、上下文长度、检索能力、幻觉减少)其实也可以服务于 RAG 系统的能力提升。
总结 Link to heading
本文首先梳理了 RAG 系统的详细结构,将简单的索引、检索、生成阶段细分成了查询翻译、路由、查询构建、索引、检索等多个阶段。然后介绍了各个阶段可能的调优方案,包括 Multi-query、RAG-Fusion、Step-back、Decomposition、HyDE、数据源路由、Prompt 路由、Function Calling、多表征索引、分层索引、特化词嵌入、CRAG 和 Adaptive RAG 等方法。
实验证明,不同阶段的调优方案,有些专注于效果提升(如 Multi-query,分层索引等),有些显著减少了 RAG 索引时间(CRAG,Adaptive RAG 等),为构建一个生产可用的 RAG 系统提供了不少思路。
参考文献 Link to heading
freeCodeCamp.org. Learn RAG From Scratch – Python AI Tutorial from a LangChain Engineer[Z]. 2024.
Rihard J. from a Former high-level employee at $MSFT who also worked with OpenAI from the $MSFT side. Key insights from the interview: 1. When they tested Copilot, productivity gains were average in the 60-70% range. Copilot’s… https://t.co/SFKxuTvolf” / X[EB/OL]. (2024-04-10)[2024-05-04]. https://twitter.com/RihardJarc/status/1778082161595208124.
Rackauckas Z. RAG-Fusion: a New Take on Retrieval-Augmented Generation[J]. International Journal on Natural Language Computing, 2024, 13(1): 37-47.
Gao L, Ma X, Lin J, et al. Precise Zero-Shot Dense Retrieval without Relevance Labels[A]. arXiv, 2022.
Chen T, Wang H, Chen S, et al. Dense X Retrieval: What Retrieval Granularity Should We Use?[A]. arXiv, 2023.
Khattab O, Zaharia M. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT[A]. arXiv, 2020.
Yan S Q, Gu J C, Zhu Y, et al. Corrective Retrieval Augmented Generation[A]. arXiv, 2024.
Jeong S, Baek J, Cho S, et al. Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity[A]. arXiv, 2024.
LangChain. Is RAG Really Dead? Testing Multi Fact Retrieval & Reasoning in GPT4-128k[Z]. 2024.